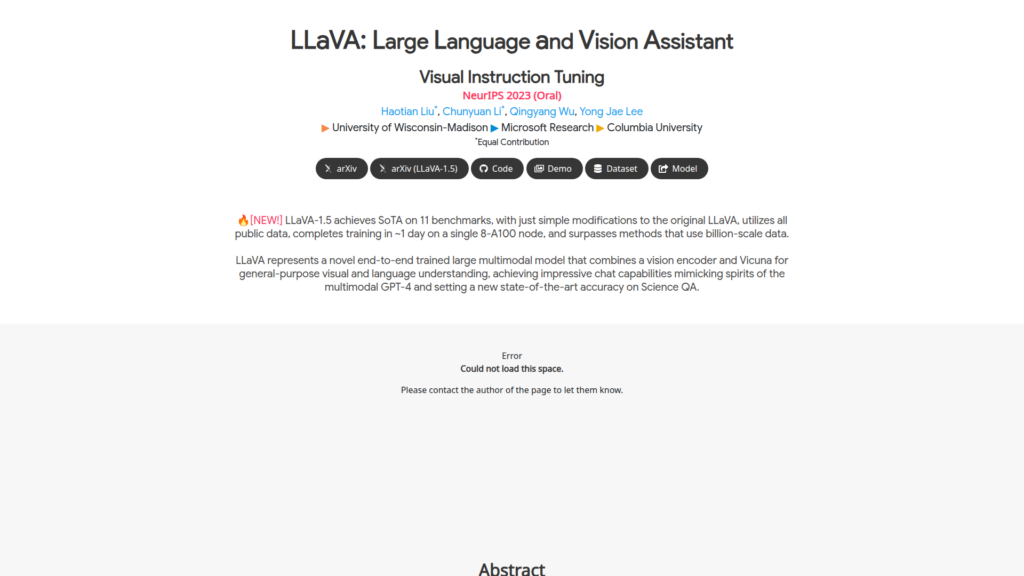
Descrição do site: Página oficial de um projeto de inteligência artificial multimodal de código aberto chamado LLaVA (Large Language and Vision Assistant), que combina visão computacional e modelos de linguagem para permitir interações em linguagem natural capazes de entender, descrever e raciocinar sobre conteúdos visuais como imagens e texto de forma integrada. A iniciativa, mantida como parte de uma organização no GitHub, explora técnicas de visual instruction tuning para treinar modelos que interpretam entrada mista — texto com imagens — e respondem com explicações, legendas ou respostas contextualizadas, aproximando-se do desempenho de modelos multimodais avançados como GPT-4V em algumas tarefas de pesquisa. Na prática, a página serve como um ponto central para documentação, exemplos, blog e demonstrações relacionadas às diferentes variantes e evoluções do LLaVA, incluindo versões com capacidades ampliadas de raciocínio, tradução visual e aplicações em vídeo e 3D. Esse projeto é voltado principalmente para pesquisa, desenvolvimento e experimentação em modelos de linguagem e visão e é de acesso público para desenvolvedores e pesquisadores interessados em construir ou testar assistentes multimodais e aplicações avançadas de IA.
Idioma padrão: Inglês
Link para o site: LLaVA